これの続き。
日本語認識の結果が微妙だったので、もう少し賢くならないかやってみます。
-

-
Python+Tesseractで画像から文章を読み取る
仕事で画像から文字を読み取ってごにょごにょしないといけなくなったのですが、なかなか精度が出ないのでいろいろ試してます。 目次1 環境準備1.1 Tesseract1.2 pyocr1.3 openCV ...
続きを見る
てな内容を10月に書こうと思ってたんですが、ものすごく遅刻しました。
というのも、Tesseract Windows版、マジで学習が終わらない。。。
学習用のデータが数百行くらいなら問題ないですが、大量に学習させようとするともう駄目でした。
結局、1ヶ月以上動かし続けても終わらなかったので諦めましたが、供養のためにやり方だけ置いときます。
目次
Tesseractに日本語を学習させる
Tesseractにはもともと日本語の学習データが用意されていて、前回はそれを使用しました。
結果は前回の通り。
この学習データには日本語で使用される主要な漢字が網羅されていないようです。
Tesseractには独自の学習データを作るためのツールが用意されているので、不足している日本語を学習させてみます。
Linuxの場合
こちらの記事を参照。

macの場合
どうやら非対応のようです。。。
Windowsの場合
jTessBoxEditorというツールを使用します。
ツールのダウンロード
ここからjTessBoxEditor-2.2.1.zipをダウンロードします。
任意の場所に解凍してください。
ファイルパスに日本語が含まれていると動かない
ので注意。
jTessBoxEditor.jarをダブルクリックするとツールが起動します。
Boxファイルの作成
学習させるのに必要な文字が描画された画像を自動で作成します。
学習対象のフォントを調べる
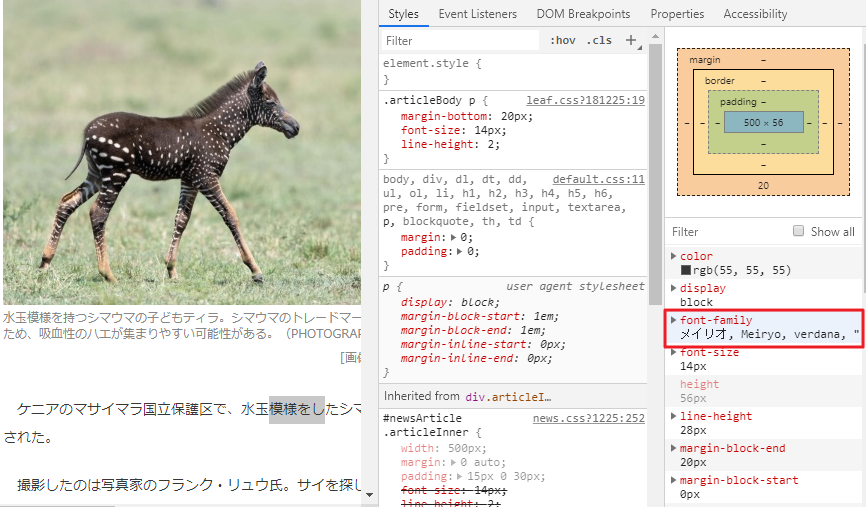
OCRで読み取る文字と同じフォントのほうが精度が上がるので、前回のナショジオの記事のフォントを調べます。
chromeの場合は
- F12を押す
- 文字(日本語部分)をドラッグして反転
- 右クリックして検証を選択
すると、フォントが表示されます。
ナショジオではメイリオを使っているようです。
jTessBoxEditorにフォントを設定する
TIFF/Box Generatorタブをクリックします。
Generateボタンが表示されない場合はウィンドウを広げてください。
フォントが書かれたボタンをクリックします。

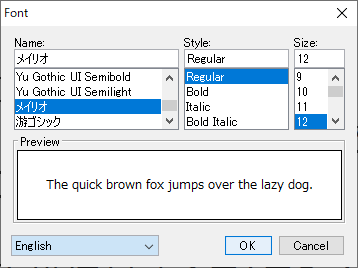
対象のフォントを選択します。
ここにフォントがない場合は、先にフォントのインストールを行ってください。
先ほどchromeで確認したメイリオを選択しました。
Styleは対象の文字がすべてイタリックで書かれている、などでなければRegularでいいと思います。
学習させたい文字を張り付ける
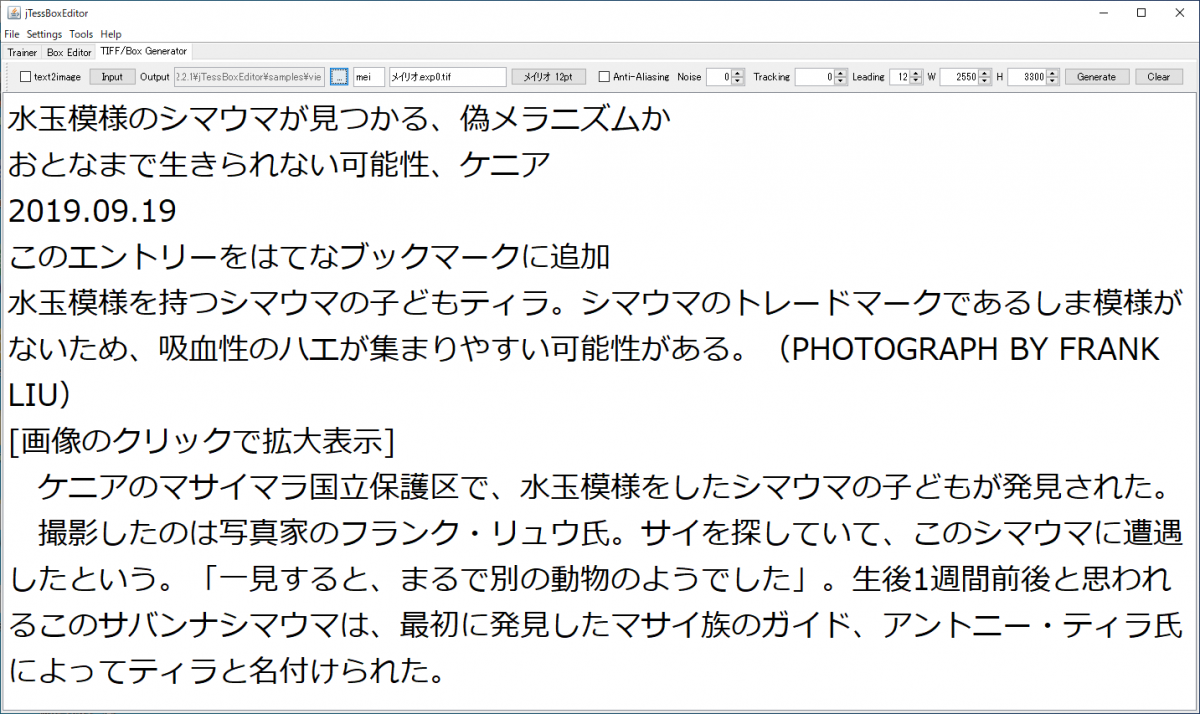
学習させる文字列を、直接コピペで貼り付けます。
※量が多い場合はInputボタンを押すとファイルを選択できます
内容は
- 覚えさせたい文字を含んだ
- ある程度意味が通った文章
がいいらしいのですが…1つ問題が。
この学習にもTesseractを使用するのですが、こいつ、GPU対応してないんです。。。
正確に言うと、一応OpenCLには対応してるけどバグあるから修正する気がある人にしか勧めないよ、とのこと。
で、ファイルサイズ3MBくらいの日本語をRyzen2400Gで学習させたのですが、1ヶ月かかっても学習が終わらず。。。
途中ブレーカー飛ばしてPCが強制シャットダウンされたり。。。
これだとお試しとして全然よろしくないので、もっと簡単に、シマウマの記事をそのままコピって貼り付けました。
出力ファイル名の設定
最後に、適当に名前を付けます。
3文字で~みたいな雰囲気がありますが、4文字でやっても動いたので、長すぎなければなんでもよさそうです。
最後にGenerateボタンをクリックします。

文字が多い場合は、文字の貼り付けもGenerateもかなり時間がかかります。
特に何のログも出してくれないのでフリーズしたかと思ってしまいますが、気長に待ちましょう。
こんなダイアログが出たら完了です。

問題がなければ、以下のファイルができているはずです。
jTessBoxEditor\samples\vie\mei.メイリオ.exp0.box
jTessBoxEditor\samples\vie\mei.メイリオ.exp0.tif
jTessBoxEditor\samples\vie\mei.font_properties
もしファイルが吐かれない場合は、Output先を変更してみてください。

作成した文字画像を確認する
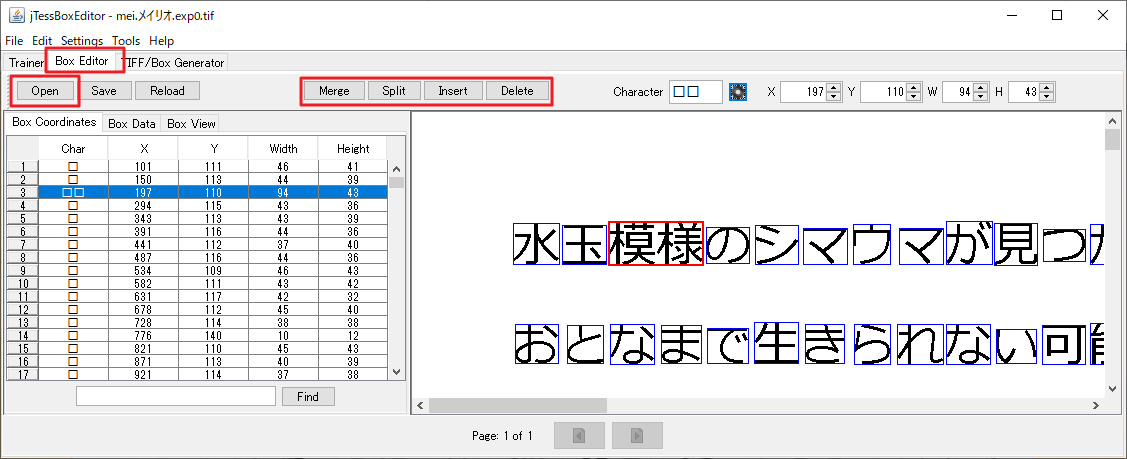
Box Editorタブをクリックします。
Openボタンからmei.メイリオ.exp0.tifを開くと、文字の認識状態が表示されます。
ここで正しく認識されない場合、例えば漢字の偏(へん)と旁(つくり)が分かれて認識された場合は、青のボックスをそれぞれ選択してMergeボタンを押すことで1つの漢字として認識させることができます。
(今回は正しく認識されたので、模・様を1つにMergeしてみました)
ただあまりにも認識率が悪い場合は、TIFF/Box Generatorタブでフォントサイズを大きくしたり、文字の間にスペースを入れたりして再作成したほうがよさそうです。
学習を行う
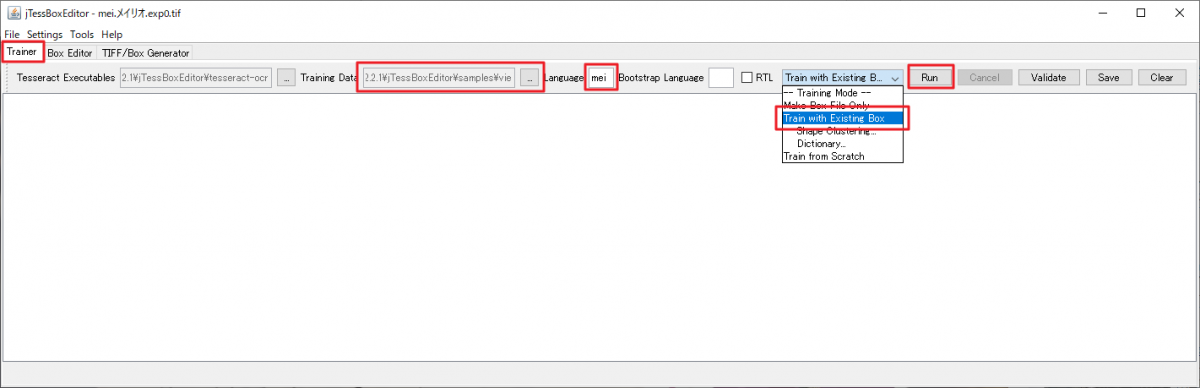
Trainerタブをクリックします。
- Training Data:mei.メイリオ.exp0.box
- Language:mei
- Training Mode:Train with Existing Box
を設定してRunボタンをクリックします。
Training completedと表示されたら学習完了です。
再度OCRしてみる
作成されたmei.traineddataを前回インストールしたTesseractのtessdataディレクトリにコピーします。
すべてのユーザーにインストールした場合は
C:\Program Files\Tesseract-OCR\tessdata
特定のユーザーにインストールした場合は、うろ覚えですが
C:\Users\ユーザー名\AppData\Local\Tesseract-OCR\tessdata
だったような。
次に、ソースの22行目をlang = 'mei+jpn'に修正します。
※複数の学習データを使いたい場合は+でつなぎます
ついでに、jpn.pngをコピーしてmei+jpn.pngを作成しておきます。
実行して前回の結果と比べてみると…
全く変わりませんでした!!
まぁ、今認識してるのと同じ内容じゃ変わらないよね…。
これで終わってしまうとアレなので、シマウマの生態について書いてある文章をコピって学習させてみました。
※これだと13秒くらいで終了
※jTessBoxEditor\samples\vieに他のboxデータがあると、それも学習しようとして終わらなくなるので削除しておく
全く変わりませんでした!!
うーん、やはりこの程度の学習では変わらないのか。。。
会社でやったときは多めのデータとフォントを合わせて学習させたところ改善が見られたので、効果がないわけではない。
ただ、学習データが少なすぎると何も変わらない…って感じですかね。
結局何の役にも立たない結果となりましたが、興味がある人は試してみてください。
OCRしたいならGoogleがいいよ
困ったときのGoogle。
なんと、Google driveでOCRができます。
Google Cloud Vision APIは、有料だけど精度はかなりよかったです。
データ量がものをいうようなやつは、大手のツールを使うのが1番ってことですかねー。
