仕事で画像から文字を読み取ってごにょごにょしないといけなくなったのですが、なかなか精度が出ないのでいろいろ試してます。
環境準備
AnacondaでPythonがインストールされていることを前提とします。
今回はWindows+Python3.7を使用。
Tesseract
GitHubを見ると、Windowsの場合はインストーラを使えと書いてあります。
UB-Mannheim/tesseract からTesseract 5.0.0のインストーラをダウンロードします。
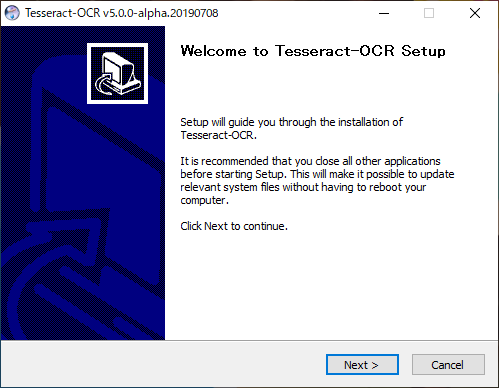
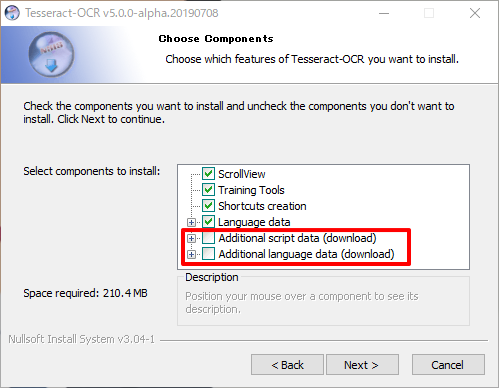
Additional script dataとAdditional language dataの+アイコンをクリックします。

Additional script dataのJapanese script、Japanese vertical scriptをチェック
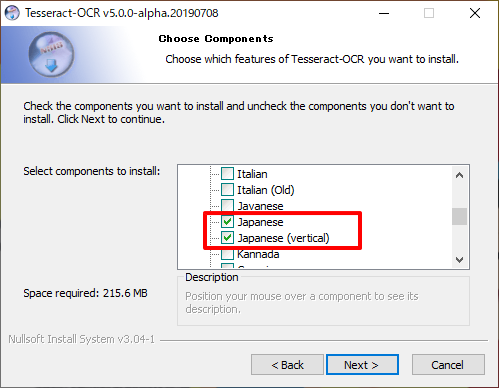
Additional language dataのJapanese、Japanese(vertical)をチェック
verticalは縦書き用の学習データのようです。
Javaneseってなんだろな…?
インストール後にパスを通すので、ファイルパスを控えておきます。
インストールが完了したら、控えておいたファイルパスにパスを通して準備完了。
CMDでtesseract -vと入力し、以下が表示されればOKです。
|
1 2 3 4 5 6 7 8 |
>tesseract -v tesseract v5.0.0-alpha.20190708 leptonica-1.78.0 libgif 5.1.4 : libjpeg 8d (libjpeg-turbo 1.5.3) : libpng 1.6.34 : libtiff 4.0.9 : zlib 1.2.11 : libwebp 0.6.1 : libopenjp2 2.3.0 Found AVX2 Found AVX Found SSE Found libarchive 3.3.2 zlib/1.2.11 liblzma/5.2.3 bz2lib/1.0.6 liblz4/1.7.5 |
pyocr
Pythonからtesseractを使うためのライブラリです。
一応Anaconda cloudで検索すると3つほど出てくるのですが、一番ダウンロードされているbrianjmcguirk/pyocrを入れてみるとPython3.7の場合はpipで入れろと表示されました。
condaで揃えたいけど仕方ないのでpipで入れます。
|
1 |
pip install pyocr |
openCV
画像を読み込んでいろいろ処理するため、openCVを入れます。
現時点だと4.1.1が入ります。
3系と4系で関数の引数が変更になってたりするので注意。
|
1 |
conda install -c conda-forge opencv |
画像読み込み
ナショジオの記事をキャプチャして、文字を読み込んでみます。
日本語版と英語版をそれぞれ用意。
名前はjpn.pngとeng.pngとします。

ソースはこんな感じ。
ocr.py
└img
├eng.png
└jpn.png
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 |
from PIL import Image import sys import pyocr import pyocr.builders import cv2 tools = pyocr.get_available_tools() if len(tools) == 0: print("No OCR tool found") sys.exit(1) tool = tools[0] print("Will use tool '%s'" % (tool.get_name())) langs = tool.get_available_languages() print("Available languages: %s" % ", ".join(langs)) lang = langs[0] print("Will use lang '%s'" % (lang)) lang = 'eng' img_path = './img/{}.png'.format(lang) img = Image.open(img_path) out_path = './img/{}_{}.png' # 読み取ったテキストを返す print('=============================================') print('TextBuilder') print('=============================================') txt = tool.image_to_string( img, lang=lang, builder=pyocr.builders.TextBuilder() ) print(txt) # 単語ごとにテキストと座標を返す print('=============================================') print('WordBoxBuilder') print('=============================================') word_boxes = tool.image_to_string( img, lang=lang, builder=pyocr.builders.WordBoxBuilder() ) out = cv2.imread(img_path) for d in word_boxes: print(d.content) print(d.position) cv2.rectangle(out, d.position[0], d.position[1], (0, 0, 255), 2) cv2.imwrite(out_path.format(lang, 'word_boxes'), out) # ラインごとにテキストと座標を返す print('=============================================') print('LineBoxBuilder') print('=============================================') line_and_word_boxes = tool.image_to_string( img, lang=lang, builder=pyocr.builders.LineBoxBuilder() ) out = cv2.imread(img_path) for d in line_and_word_boxes: print(d.content) print(d.position) cv2.rectangle(out, d.position[0], d.position[1], (0, 0, 255), 2) cv2.imwrite(out_path.format(lang, 'line_and_word_boxes'), out) # 数値のみを読み取って返す print('=============================================') print('DigitBuilder') print('=============================================') digits = tool.image_to_string( img, lang=lang, builder=pyocr.tesseract.DigitBuilder() ) print(digits) |
英語の読み取り
22行目をlang = 'eng'として実行します。
出力されるテキストはこんな感じ。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 263 264 265 266 267 268 269 270 271 272 273 274 275 276 277 278 279 280 281 282 283 284 285 286 287 288 289 290 291 292 293 294 295 296 297 298 299 300 301 302 303 304 305 306 307 308 309 310 311 312 313 314 315 316 317 318 319 320 321 322 323 324 325 326 327 328 329 330 331 332 333 334 335 336 337 338 339 340 341 342 343 344 345 346 347 348 349 350 351 352 353 354 355 356 357 358 359 360 361 362 363 364 365 366 367 368 369 370 371 372 373 374 375 376 377 378 379 380 381 382 383 384 385 386 387 388 389 390 391 392 393 394 |
============================================= TextBuilder ============================================= eae Bonet Sob RAD 3 Tira, the spotted zebra foal, may be more suspectible to biting flies without the zebra's trademark str ANIMALS | WEIRD & WILD Rare polka-dotted zebra foal photographed in Kenya The eye-catching animal, seen in Kenya's Masai Mara National Reserve, likely has a genetic mutation called pseudomelanism. BY KATIE STACEY f uo Talk about a horse of another color—a zebra foal with a dark coat and white polka dots has been spotted in Kenya’s Masai Mara National Reserve. Photographer Frank Liu was on the search for rhinos recently when he noticed the eye-catching plains zebra, likely about a week old. “At first glance he > Liu says. Antony Tira, a Maasai looked like a different species altogether, guide who first spotted the foal, named him Tira. ============================================= WordBoxBuilder ============================================= ((59, 98), (467, 336)) eae ((13, 285), (63, 329)) Bonet ((84, 283), (140, 326)) Sob ((206, 303), (223, 332)) RAD ((250, 308), (292, 324)) 3 ((316, 286), (331, 323)) Tira, ((11, 356), (29, 364)) the ((36, 356), (52, 364)) spotted ((55, 356), (94, 366)) zebra ((97, 356), (124, 364)) foal, ((128, 356), (148, 366)) may ((152, 359), (173, 366)) be ((176, 356), (188, 364)) more ((192, 359), (217, 364)) suspectible ((220, 356), (276, 366)) to ((280, 359), (290, 364)) biting ((293, 356), (322, 366)) flies ((325, 356), (344, 364)) without ((349, 356), (386, 364)) the ((390, 356), (399, 364)) zebra's ((421, 356), (443, 364)) trademark ((446, 356), (498, 364)) str ((12, 372), (26, 379)) ((401, 359), (421, 364)) ((28, 374), (46, 381)) ANIMALS ((13, 451), (83, 460)) | ((88, 441), (107, 469)) WEIRD ((119, 451), (226, 460)) & ((167, 441), (182, 469)) WILD ((186, 451), (226, 460)) Rare ((13, 494), (72, 515)) polka-dotted ((81, 493), (260, 521)) zebra ((269, 493), (343, 515)) foal ((351, 493), (401, 515)) photographed ((13, 527), (210, 555)) in ((227, 534), (241, 549)) Kenya ((251, 528), (332, 555)) The ((11, 571), (35, 581)) eye-catching ((40, 571), (121, 584)) animal, ((126, 571), (170, 583)) seen ((175, 574), (203, 581)) in ((208, 571), (218, 581)) Kenya's ((223, 571), (269, 584)) Masai ((274, 571), (308, 581)) Mara ((314, 571), (343, 581)) National ((349, 571), (401, 581)) Reserve, ((407, 571), (459, 583)) likely ((464, 571), (496, 584)) has ((12, 591), (42, 601)) a ((32, 582), (37, 611)) genetic ((47, 592), (94, 604)) mutation ((99, 592), (156, 601)) called ((161, 591), (197, 601)) pseudomelanism. ((203, 591), (313, 604)) BY ((12, 654), (25, 661)) KATIE ((33, 654), (70, 661)) STACEY ((77, 654), (125, 661)) f ((411, 650), (417, 662)) uo ((468, 651), (509, 661)) Talk ((11, 754), (39, 765)) about ((43, 754), (78, 765)) a ((83, 758), (89, 765)) horse ((93, 754), (128, 765)) of ((133, 754), (145, 765)) another ((148, 754), (197, 765)) color—a ((202, 754), (252, 765)) zebra ((257, 754), (291, 765)) foal ((295, 754), (318, 765)) with ((322, 754), (349, 765)) a ((354, 758), (360, 765)) dark ((365, 754), (393, 765)) coat ((398, 756), (423, 765)) and ((428, 754), (451, 765)) white ((455, 754), (489, 765)) polka ((11, 777), (46, 791)) dots ((50, 777), (76, 788)) has ((80, 777), (101, 788)) been ((106, 777), (136, 788)) spotted ((140, 777), (187, 791)) in ((191, 777), (203, 788)) Kenya’s ((208, 778), (255, 791)) Masai ((260, 777), (298, 788)) Mara ((302, 778), (335, 788)) National ((339, 777), (393, 788)) Reserve. ((398, 778), (451, 788)) ((391, 824), (402, 835)) Photographer ((12, 824), (98, 838)) Frank ((103, 824), (140, 835)) Liu ((144, 825), (164, 835)) was ((168, 828), (192, 835)) on ((197, 828), (212, 835)) the ((216, 824), (235, 835)) search ((240, 824), (280, 835)) for ((285, 824), (302, 835)) rhinos ((307, 824), (346, 835)) recently ((351, 826), (390, 835)) when ((405, 824), (439, 835)) he ((443, 824), (458, 835)) noticed ((463, 824), (509, 835)) the ((11, 847), (31, 858)) eye-catching ((35, 847), (115, 861)) plains ((119, 847), (156, 861)) zebra, ((161, 847), (198, 861)) likely ((203, 847), (235, 861)) about ((241, 847), (276, 858)) a ((281, 851), (287, 858)) week ((291, 847), (323, 858)) old. ((327, 847), (350, 858)) “At ((355, 848), (375, 858)) first ((379, 847), (404, 858)) glance ((409, 847), (448, 861)) he ((453, 847), (467, 858)) > ((274, 871), (276, 875)) Liu ((281, 870), (301, 881)) says. ((306, 874), (325, 881)) Antony ((333, 872), (385, 881)) Tira, ((389, 870), (418, 884)) a ((423, 874), (430, 881)) Maasai ((434, 870), (479, 881)) ((326, 874), (331, 881)) looked ((11, 870), (53, 881)) like ((57, 870), (80, 881)) a ((84, 874), (91, 881)) different ((95, 870), (149, 881)) species ((154, 874), (198, 884)) altogether, ((203, 870), (267, 884)) ((268, 879), (270, 882)) guide ((11, 893), (45, 907)) who ((50, 893), (75, 904)) first ((80, 893), (106, 904)) spotted ((110, 893), (156, 907)) the ((161, 893), (180, 904)) foal, ((185, 893), (211, 905)) named ((216, 893), (259, 904)) him ((263, 893), (287, 904)) Tira. ((292, 894), (321, 904)) ============================================= LineBoxBuilder ============================================= ((59, 98), (467, 336)) eae Bonet Sob RAD 3 ((13, 283), (331, 332)) Tira, the spotted zebra foal, may be more suspectible to biting flies without the zebra's trademark ((11, 356), (498, 366)) str ((12, 372), (26, 379)) ((401, 359), (421, 364)) ((28, 374), (46, 381)) ANIMALS | WEIRD & WILD ((13, 451), (226, 460)) Rare polka-dotted zebra foal ((13, 493), (401, 521)) photographed in Kenya ((13, 527), (332, 555)) The eye-catching animal, seen in Kenya's Masai Mara National Reserve, likely ((11, 571), (496, 584)) has a genetic mutation called pseudomelanism. ((12, 591), (313, 604)) BY KATIE STACEY f uo ((12, 650), (509, 662)) Talk about a horse of another color—a zebra foal with a dark coat and white ((11, 754), (489, 765)) polka dots has been spotted in Kenya’s Masai Mara National Reserve. ((11, 777), (451, 791)) ((391, 824), (402, 835)) Photographer Frank Liu was on the search for rhinos recently when he noticed ((12, 824), (509, 838)) the eye-catching plains zebra, likely about a week old. “At first glance he ((11, 847), (467, 861)) > Liu says. Antony Tira, a Maasai ((274, 870), (479, 884)) ((326, 874), (331, 881)) looked like a different species altogether, ((11, 870), (267, 884)) ((268, 879), (270, 882)) guide who first spotted the foal, named him Tira. ((11, 893), (321, 907)) ============================================= DigitBuilder ============================================= 9 3 . - -.. . . -.. . . .. |
英語だと、結構な精度で読み取れてますね。
WordBoxBuilderの結果を見ると、ちゃんと単語ごとで区切ってくれてます。
WordBoxBuilderとLineBoxBuilderの出力画像を見てみると、グレーの文字は読み取れてないものの、かなりいい線いってます。
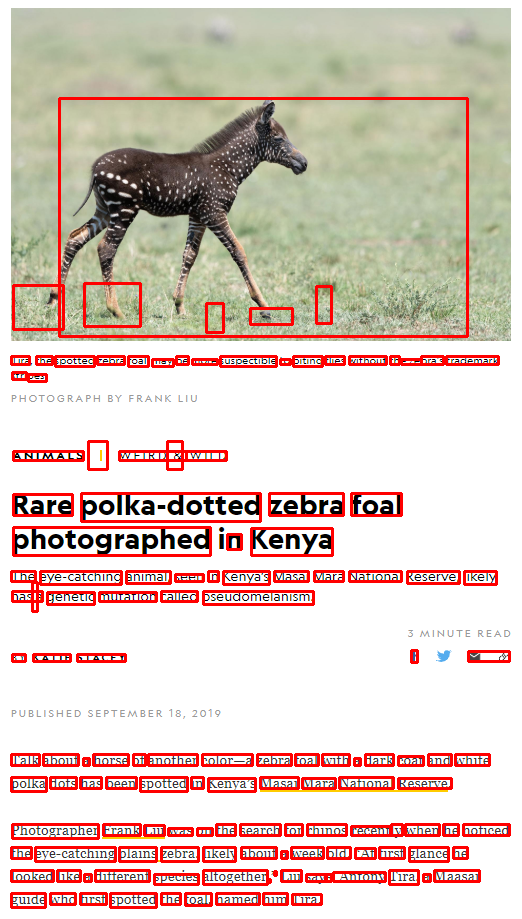
eng_word_boxes.png
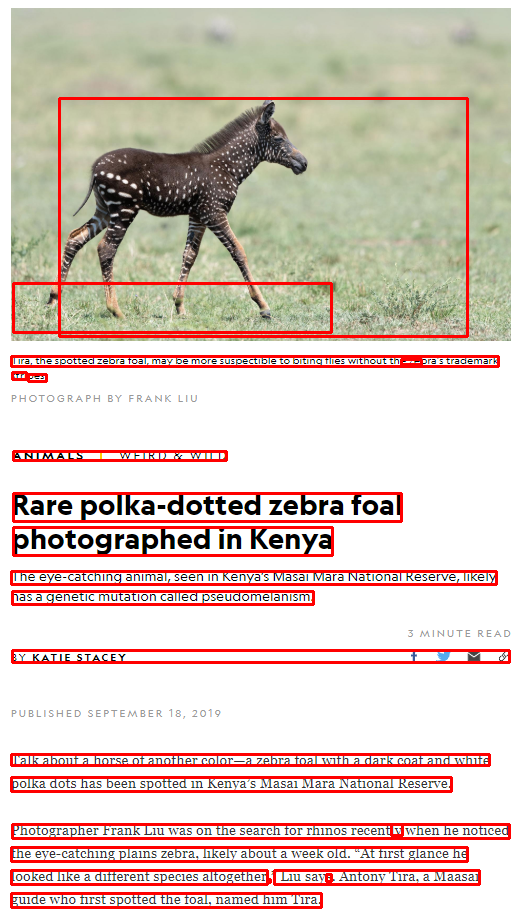
eng_line_and_word_boxes.png
日本語の読み取り
22行目をlang = 'jpn'として実行します。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 263 264 265 266 267 268 269 270 271 272 273 274 275 276 277 278 279 280 281 282 283 284 285 286 287 288 289 290 291 292 293 294 295 296 297 298 299 300 301 302 303 304 305 306 307 308 309 310 311 312 313 314 315 316 317 318 319 320 321 322 323 324 325 326 327 328 329 330 331 332 333 334 335 336 337 338 339 340 341 342 343 344 345 346 347 348 349 350 351 352 353 354 355 356 357 358 359 360 361 362 363 364 365 366 367 368 369 370 371 372 373 374 375 376 377 378 379 380 381 382 383 384 385 386 387 388 389 390 391 392 393 394 395 396 397 398 399 400 401 402 403 404 405 406 407 408 409 410 411 412 413 414 415 416 417 418 419 420 421 422 423 424 425 426 427 428 429 430 431 432 433 434 435 436 437 438 439 440 441 442 443 444 445 446 447 448 449 450 451 452 453 454 455 456 457 458 459 460 461 462 463 464 465 466 467 468 469 470 471 472 473 474 475 476 477 478 479 480 481 482 483 484 485 486 487 488 489 490 491 492 493 494 495 496 497 498 499 500 501 502 503 504 |
============================================= TextBuilder ============================================= 水玉模様のシマウマが見つかる、偽メラニズムか おとなまで生きられない可能性、ケニア 2019.0919 Zi PrrTEE ロ 水玉筐様を持つシマウマの子どもティラ。 シマウマのトレードマークであるしま機様がない ため、唄血竹のハエが集まりやすい可能性がある。 (PHOTOGRAPH BY FRANK LU) [画像のクリックで拡大表示] ケニアのマサイマラ| された。 保護区で、水玉模様をしたシマウマの子どもが発見 撮影したのは写真家のフランク・リユウ氏。サイを探していて、このシマウ マに遭遇したという。「一見すると、まるで別の動物のようでした」 。 生後1週 間前後と思われるこのサバンナシマウマは、時初に発見したマサイ族のカイ ド、アントニー・ティラ氏によってティラと名付けられた。 ============================================= WordBoxBuilder ============================================= 水玉 ((21, 12), (71, 35)) 模様 ((73, 12), (382, 36)) の ((143, 7), (177, 47)) シマ ((160, 7), (221, 47)) ウマ ((200, 7), (261, 47)) が ((240, 7), (281, 47)) 見 ((293, 7), (334, 47)) つか ((313, 7), (371, 47)) る ((353, 7), (388, 47)) 、 ((386, 27), (394, 35)) 偽 ((411, 12), (460, 35)) メラ ((440, 7), (486, 47)) ニズム ((489, 7), (566, 47)) か ((567, 13), (592, 35)) お ((21, 49), (36, 62)) と ((39, 49), (51, 62)) な ((53, 49), (68, 63)) まで ((70, 49), (97, 63)) 生き ((101, 49), (131, 63)) られ ((134, 49), (164, 63)) な ((165, 49), (180, 63)) い ((182, 51), (189, 62)) 可 ((191, 49), (223, 63)) 能 ((229, 48), (248, 63)) 性 ((241, 44), (260, 72)) 、 ((250, 44), (269, 72)) ケ ((261, 49), (277, 63)) ニア ((277, 50), (308, 63)) 2019.0919 ((22, 79), (110, 125)) Zi ((456, 78), (530, 124)) PrrTEE ((529, 78), (630, 124)) ロ ((642, 93), (660, 110)) 水玉 ((91, 524), (118, 552)) 筐 ((115, 531), (141, 543)) 様 ((138, 524), (148, 552)) を ((143, 524), (153, 552)) 持つ ((157, 532), (185, 543)) シマ ((175, 524), (199, 552)) ウマ ((200, 532), (223, 543)) の ((215, 524), (234, 552)) 子ども ((241, 524), (281, 552)) ティ ((271, 524), (293, 552)) ラ ((296, 536), (311, 543)) 。 ((304, 524), (318, 552)) シマ ((320, 533), (343, 543)) ウマ ((344, 532), (367, 543)) の ((367, 533), (379, 543)) トレ ((382, 532), (403, 543)) ー ((404, 537), (414, 538)) ド ((418, 532), (426, 543)) マー ((427, 532), (498, 543)) ク ((446, 524), (465, 552)) で ((455, 524), (475, 552)) ある ((465, 532), (498, 543)) し ((501, 532), (510, 543)) ま ((512, 532), (519, 543)) 機 ((523, 531), (582, 543)) 様 ((551, 524), (556, 552)) が ((553, 524), (559, 552)) な ((558, 524), (573, 552)) い ((565, 524), (580, 552)) た ((91, 548), (102, 559)) め ((103, 548), (114, 559)) 、 ((116, 556), (119, 559)) 唄 ((127, 547), (150, 559)) 血 ((151, 548), (163, 559)) 竹 ((163, 549), (174, 559)) の ((175, 549), (179, 559)) ハエ ((173, 540), (202, 568)) が ((192, 540), (211, 568)) 集まり ((215, 548), (253, 559)) や ((243, 540), (262, 568)) すい ((260, 548), (281, 559)) 可能 ((283, 547), (359, 559)) 性 ((311, 540), (330, 568)) が ((320, 540), (339, 568)) ある ((329, 540), (358, 568)) 。 ((350, 540), (365, 568)) (PHOTOGRAPH ((375, 548), (460, 559)) BY ((466, 549), (481, 558)) FRANK ((486, 549), (525, 558)) LU) ((530, 548), (554, 559)) [画像 ((429, 572), (491, 584)) の ((462, 565), (477, 593)) クリ ((469, 572), (491, 584)) ッ ((494, 575), (502, 583)) ク ((505, 572), (514, 583)) で ((517, 573), (523, 583)) 拡大 ((530, 565), (551, 593)) 表示 ((552, 565), (575, 593)) ] ((576, 572), (579, 584)) ((86, 144), (596, 564)) ケニア ((105, 623), (230, 635)) の ((138, 618), (164, 643)) マサ ((153, 618), (191, 643)) イマ ((178, 618), (216, 643)) ジラ ((211, 618), (224, 643)) 国立 ((221, 618), (270, 643)) 保護 ((255, 618), (299, 643)) 区 ((301, 624), (308, 634)) で ((298, 618), (316, 643)) 、 ((316, 631), (319, 634)) 水 ((329, 622), (342, 635)) 玉 ((343, 623), (356, 635)) 模 ((357, 622), (385, 635)) 様 ((390, 623), (398, 635)) を ((401, 623), (410, 635)) し ((414, 623), (426, 635)) た ((428, 623), (437, 635)) シマ ((426, 618), (455, 643)) ウマ ((456, 622), (483, 635)) の ((483, 624), (496, 635)) 子ども ((503, 623), (537, 635)) が ((539, 623), (548, 635)) 発見 ((548, 622), (580, 635)) され ((92, 651), (118, 663)) た ((120, 651), (130, 663)) 。 ((134, 659), (138, 663)) 撮影 ((105, 699), (146, 711)) し ((148, 699), (160, 711)) た ((161, 700), (168, 711)) の ((159, 694), (176, 719)) は ((176, 699), (185, 711)) 写真 ((189, 698), (300, 711)) 家 ((219, 694), (241, 719)) の ((230, 694), (256, 719)) フ ((242, 694), (268, 719)) ラン ((255, 694), (293, 719)) ク ((280, 694), (306, 719)) ・ ((306, 704), (309, 707)) リ ((317, 699), (327, 711)) ユウ ((330, 698), (356, 711)) 氏 ((358, 699), (376, 711)) 。 ((365, 694), (387, 719)) サ ((385, 699), (399, 711)) イ ((400, 699), (412, 711)) を ((414, 699), (426, 711)) 探し ((442, 699), (468, 711)) て ((470, 700), (482, 710)) いて ((471, 699), (501, 711)) 、 ((496, 694), (518, 719)) こ ((513, 700), (524, 711)) の ((525, 700), (538, 711)) シマ ((540, 699), (567, 711)) ウ ((568, 698), (576, 711)) マ ((92, 728), (105, 739)) に ((106, 727), (116, 739)) 遭遇 ((119, 726), (222, 739)) し ((148, 722), (170, 747)) た ((158, 722), (180, 747)) と ((169, 722), (195, 747)) いう ((183, 726), (216, 739)) 。「 ((204, 722), (244, 747)) 一 ((246, 727), (272, 739)) 見 ((274, 726), (286, 739)) する ((288, 727), (311, 739)) と ((316, 735), (319, 738)) 、 ((310, 722), (332, 747)) ま ((330, 727), (342, 739)) る ((344, 728), (355, 739)) で ((357, 728), (370, 738)) 別 ((373, 727), (383, 739)) の ((385, 728), (393, 739)) 動物 ((399, 726), (516, 739)) の ((431, 722), (453, 747)) よう ((442, 722), (476, 747)) で ((465, 722), (486, 747)) し ((475, 722), (497, 747)) た ((485, 722), (507, 747)) 」 ((498, 722), (516, 747)) 。 ((515, 722), (528, 747)) 生後 ((526, 726), (589, 739)) 1 ((565, 722), (574, 747)) 週 ((583, 722), (593, 747)) 間 ((92, 754), (117, 767)) 前 ((119, 754), (201, 767)) 後 ((131, 749), (145, 775)) と ((137, 749), (151, 775)) 思わ ((148, 754), (188, 767)) れる ((174, 749), (214, 775)) この ((202, 749), (230, 775)) サバ ((231, 754), (259, 767)) ン ((260, 756), (272, 767)) ナ ((273, 754), (286, 767)) シマ ((288, 755), (315, 767)) ウマ ((316, 754), (343, 767)) は ((344, 755), (355, 767)) 、 ((358, 763), (361, 766)) 時 ((371, 754), (394, 767)) 初 ((400, 755), (402, 767)) に ((404, 756), (411, 766)) 発見 ((413, 753), (566, 767)) し ((449, 749), (468, 775)) た ((458, 749), (476, 775)) マサ ((467, 749), (498, 775)) イ ((488, 749), (507, 775)) 族 ((516, 749), (535, 775)) の ((525, 749), (543, 775)) カイ ((534, 749), (567, 775)) ド ((95, 782), (109, 795)) 、 ((120, 784), (127, 795)) ア ((113, 778), (139, 803)) ント ((134, 782), (160, 795)) ニー・ ((161, 785), (197, 794)) テ ((203, 784), (216, 795)) ィ ((218, 785), (228, 795)) ラ ((232, 783), (244, 795)) 氏 ((246, 783), (269, 795)) に ((274, 783), (281, 795)) よっ ((272, 778), (298, 803)) て ((302, 784), (314, 794)) ティ ((315, 784), (340, 795)) ラ ((344, 783), (356, 795)) と ((359, 783), (369, 795)) 名 ((371, 782), (460, 796)) 付け ((393, 778), (425, 803)) られ ((416, 778), (441, 803)) た ((434, 778), (452, 803)) 。 ((443, 778), (460, 803)) ============================================= LineBoxBuilder ============================================= 水玉 模様 の シマ ウマ が 見 つか る 、 偽 メラ ニズム か ((21, 11), (592, 36)) お と な まで 生き られ な い 可 能 性 、 ケ ニア ((21, 48), (308, 63)) 2019.0919 Zi PrrTEE ロ ((22, 79), (660, 125)) ((86, 144), (596, 564)) ケニア の マサ イマ ジラ 国立 保護 区 で 、 水 玉 模 様 を し た シマ ウマ の 子ども が 発見 ((105, 622), (580, 636)) され た 。 ((92, 651), (138, 663)) 撮影 し た の は 写真 家 の フ ラン ク ・ リ ユウ 氏 。 サ イ を 探し て いて 、 こ の シマ ウ ((105, 698), (580, 711)) マ に 遭遇 し た と いう 。「 一 見 する と 、 ま る で 別 の 動物 の よう で し た 」 。 生後 1 週 ((92, 726), (589, 739)) 間 前 後 と 思わ れる この サバ ン ナ シマ ウマ は 、 時 初 に 発見 し た マサ イ 族 の カイ ((92, 753), (566, 767)) ド 、 ア ント ニー・ テ ィ ラ 氏 に よっ て ティ ラ と 名 付け られ た 。 ((95, 782), (460, 796)) ============================================= DigitBuilder ============================================= 2019.0919 - . 1 |
WordBoxBuilderとLineBoxBuilderの出力画像がこれ。
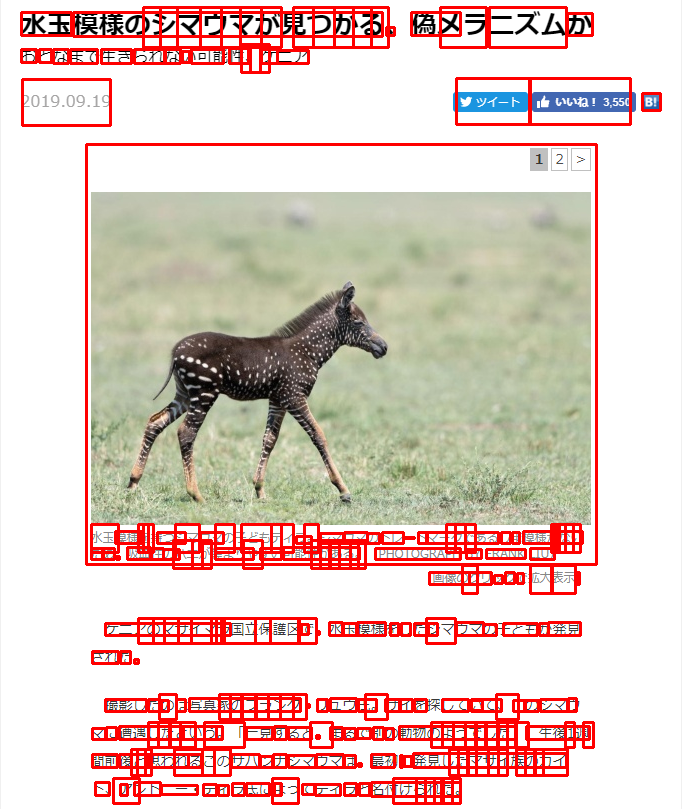
jpn_word_boxes.png
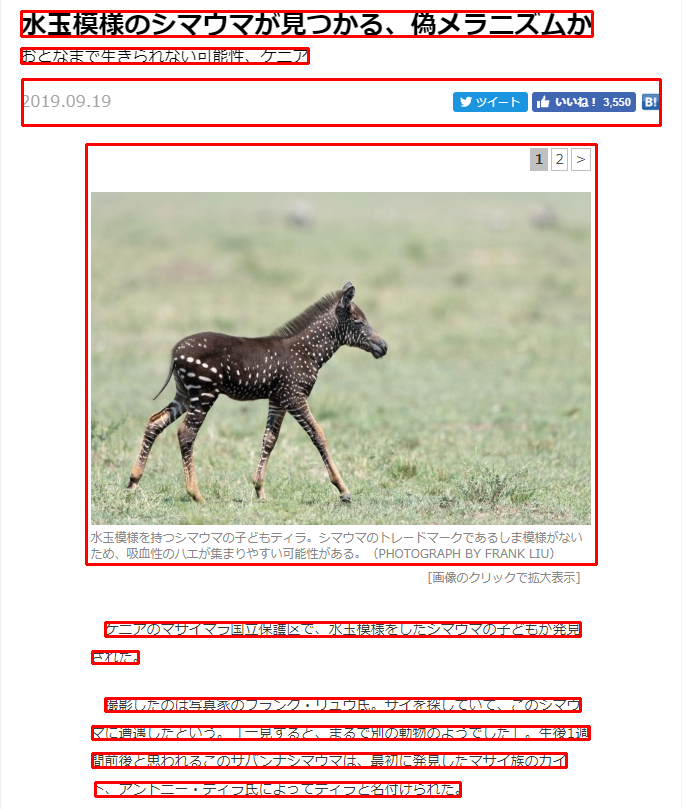
jpn_line_and_word_boxes.png
WordBoxBuilderの結果を見ると、単語の認識がかなり微妙ということがわかります。
文字を読みとるだけならTextBuilderもしくはLineBoxBuilderを使用すればいいですが、WordBoxBuilderで単語区切りにしたい場合はこのままだと使い物になりません。
精度を向上させるには
Tesseractには、最初から学習データが用意されています。
先ほどの読み取りもこちらを使用しました。
このデータで精度が出ない場合は、自分で学習データを作ることができます。
自分で学習させた場合、特定のフォントや手書き文字の精度が上がる場合があります。
日本語の単語を読み取ってくれない問題も同様に。
長くなったので、学習は次回行いたいたいと思います。
