最近、仕事でもちょこちょこ機械学習をいじることが増えてきて、家でも書いてます。
目次
神獣ベコたちを分類しようと思った
先日のことです。
イオンモール川口前川店はまだまだありました。
私は1番ダメなパターンにハマって、うっかりコンプしました。
後ほど、ダブったベコたちの里親様を募集します。#神獣ベコたち #赤ベコ— はじっこ@フルリモート希望 (@snapstroll) August 16, 2019

ということで、うっかり5種をコンプリートしてしまいました。

いやね、コンプする予定はなかったんですよ。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 |
import random bekos = ['ケルベコス','ユニベコーン','キマイラベコ','ミノタウベコ','ベコサス'] total = 0 result = {} streak = '' while 'ケルベコス' not in result: beko = random.choice(bekos) print(beko + 'ゲットだぜ!') result.setdefault(beko, 0) result[beko] += 1 total += 300 if total + 300 > 5000: print('予算がなくなったので諦めました') break streak += beko if beko * 3 in streak: print('同じベコが3回続いたので諦めました') break print('\n【結果】') for beko in bekos: if beko in result: print('{}:{}ベコ'.format(beko, result[beko])) print('----------------------') print('合計:{}ベコ'.format(sum(result.values()))) print('金額:{}円'.format(total)) |
っていうロジックだったんですけど。
プログラム実行すると、大体3000円くらいでケルベコス引き当てるか、3連続同じの引いて処理止まるんですけど。
現実がこれ↓
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
ミノタウベコゲットだぜ! ユニベコーンゲットだぜ! キマイラベコゲットだぜ! ベコサスゲットだぜ! ユニベコーンゲットだぜ! キマイラベコゲットだぜ! ミノタウベコゲットだぜ! ユニベコーンゲットだぜ! ベコサスゲットだぜ! ユニベコーンゲットだぜ! キマイラベコゲットだぜ! ユニベコーンゲットだぜ! ケルベコスゲットだぜ! 【結果】 ケルベコス:1ベコ ユニベコーン:5ベコ キマイラベコ:3ベコ ミノタウベコ:2ベコ ベコサス:2ベコ ---------------------- 合計:13ベコ 金額:3900円 |
ちょっと引きすぎたw
最初にケルベコス以外がストレートで4種揃ったのがいけなかったよね。
やめられなくなるパターン。
(このうち4種1ベコずつは里親様のもとに旅立ちました)
で。
せっかく集めたのに使わないともったいないので、機械学習で神獣ベコたちを分類してみました。
学習用の画像を撮影する
960×960でそれぞれ50枚plus α撮りました。
本当はもっと撮る予定だったんですが、角度を変えて撮り続けるというのが意外と辛く。。。
50枚を学習用に、余った分は学習後に分類する用としました。
コードを書いていく
と言っても、今回はいろんなところのソースを参考にしたので、あまりガリガリ書いてはいません。
画像を水増しする
先述の通り学習画像を各50枚、合計250枚しか用意していません。
これでも一応60%くらいは認識するのですが、さすがに少ないので、kerasのImageDataGeneratorを使って画像を増やします。
こちらを参考に、水増し用のコードを作成。

で、できたのがこちら。
実行すると…
|
1 |
python dataset_generator.py bekos\data\kerbecos jpg |
元の画像に対して

こんなのとか

こんなのができます。

写真って、光の加減で色が変わったりするよね。
角度も毎回同じとは限らないよね。
ってことで、学習精度が上がるんだと思いますたぶん。
(水増ししすぎると過学習の原因になるので注意)
画像を読み込んで学習させる
学習用の画像ができたら、今度はモデルを使って学習させていきます。
ベースはこれを使ってます。

画像を読み込んでラベルを付ける
こちらを参考に、データセットを用意する処理を書きます。

cifar10_deep_with_aug.pyのclass CIFAR10Dataset(): get_batchを修正。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 |
class BEKOSDataset(): ・・・ def get_batch(self): folder = ['bekosus','chimairabeko','kerbecos','minotaubeko','unibecorn'] image_size = 32 X = [] Y = [] for index, name in enumerate(folder): dir = './bekos/data/' + name files = glob.glob(dir + '/*.jpg') for file in files: image = Image.open(file) image = image.convert('RGB') image = image.resize((image_size, image_size)) data = np.asarray(image) X.append(data) Y.append(index) X = np.array(X) Y = np.array(Y) #画像データを0から1の範囲に変換 X = X.astype('float32') X = X / 255.0 # 正解ラベルの形式を変換 Y = np_utils.to_categorical(Y, len(folder)) # 学習用データとテストデータ x_train, x_test, y_train, y_test = train_test_split(X, Y, test_size=0.20) return x_train, y_train, x_test, y_test ・・・ |
モデルを作成して学習する
ほとんど元の処理のままですが、一部変更。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
class Trainer(): ・・・ self._target.fit_generator( datagen.flow(x_train, y_train, batch_size=batch_size), steps_per_epoch=x_train.shape[0] // batch_size, epochs=epochs, validation_data=(x_valid, y_valid), callbacks=[ TensorBoard(log_dir=self.log_dir), ModelCheckpoint(model_path, save_best_only=True) ], verbose=self.verbose, workers=5 ) ・・・ |
fit_generatorの引数workersを、何となく4→5に上げてみました。
ここに1以上の数字を設定すると、その数だけ並列処理をしてくれるらしいです。
が、あとで調べたらWindowsは対象外とのこと。。。
macかLinuxでなら効果があると思われます。
学習にどれくらいかかるのかをログに出すコードも追加。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
# 学習の開始時刻を取得 start_time = time.time() # train the model x_train, y_train, x_test, y_test = dataset.get_batch() trainer = Trainer(model, loss='categorical_crossentropy', optimizer=RMSprop()) trainer.train( x_train, y_train, batch_size=32, epochs=50, validation_split=0.2 ) # 学習と検証の終了時刻を取得 end_time = time.time() # show result score = model.evaluate(x_test, y_test, verbose=0) print('Test loss:', score[0]) print('Test accuracy:', score[1]) # 学習処理の時間を表示 elapsed_time = end_time - start_time td = datetime.timedelta(seconds=elapsed_time) print('学習処理時間:{0}'.format(str(td))) |
これで、学習終了後に
|
1 2 3 |
Test loss: 0.372760902101 Test accuracy: 0.878181817965 学習処理時間:0:11:22.367411 |
という感じで時間が出力されます。
古いCPUだけで処理してるので、画像が少ないのに11分以上かかりました。。。
できたコードを実行すると、学習結果(重み)とログファイルが出来上がります。
コンソールで
|
1 |
tensorboard --logdir=logdir_bekos |
と実行すると、tensorboard が起動するはずですが…
|
1 2 3 4 |
Traceback (most recent call last): File "K:\python\envs\keras\Scripts\tensorboard-script.py", line 3, in <module> import tensorflow.tensorboard.tensorboard ModuleNotFoundError: No module named 'tensorflow.tensorboard' |
モジュールがないと怒られました。
たぶんtensorflowをインストールすれば動くと思うんですが、今は使わないので
|
1 |
python -m tensorboard.main --logdir=logdir_bekos |
としてみると…
|
1 |
TensorBoard 1.7.0 at http://DESKTOP-FF5QJ0K:6006 (Press CTRL+C to quit) |
無事起動しました。
もしこのURLにアクセスしても表示されない場合は、http://localhost:6006にしてみてください。
それぞれの結果がグラフで見れます。
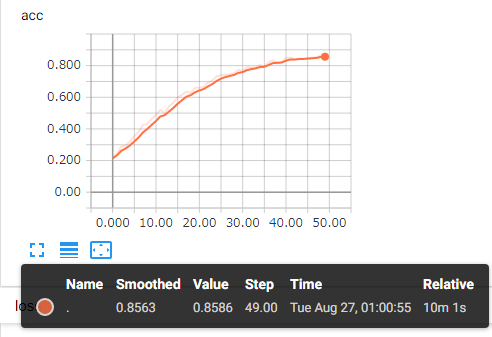
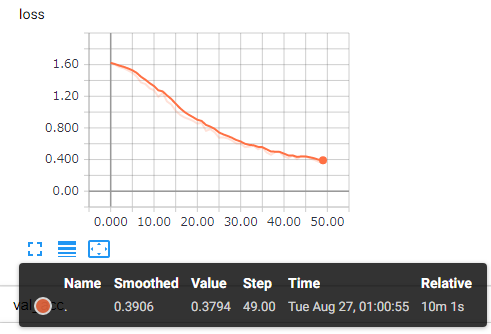
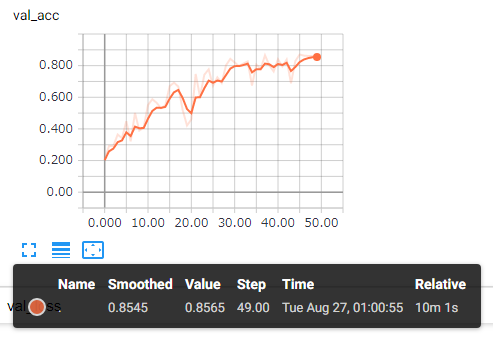
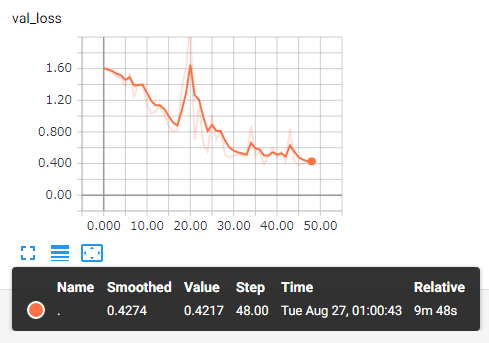
学習結果を使って画像を分類する
最後に、作成した重みを使って、画像を分類してみます。
こちらをベースに作成します。
最後の結果表示部分を書き換え。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
# 正解表示用の辞書 dic = { '0':'ベコサス', '1':'キマイラベコ', '2':'ケルベコス', '3':'ミノタウベコ', '4':'ユニベコーン' } # 結果表示 ok = 0 for i , item in enumerate(predicted): beko_name = dic[str(item)] print(image_paths[i] + 'は' + beko_name + '!') if beko_name in image_paths[i]: ok += 1 print('正解率:{}/{}({}%)'.format(ok, len(image_paths), round(ok / len(image_paths) * 100))) print('当たってた?') |
作ったコードを実行してみると…
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 |
python bekos_predict.py Using TensorFlow backend. bekos\predict\キマイラベコ (1).JPGはキマイラベコ! bekos\predict\キマイラベコ (10).JPGはキマイラベコ! bekos\predict\キマイラベコ (11).JPGはケルベコス! bekos\predict\キマイラベコ (2).JPGはキマイラベコ! bekos\predict\キマイラベコ (3).JPGはユニベコーン! bekos\predict\キマイラベコ (4).JPGはキマイラベコ! bekos\predict\キマイラベコ (5).JPGはベコサス! bekos\predict\キマイラベコ (6).JPGはキマイラベコ! bekos\predict\キマイラベコ (7).JPGはキマイラベコ! bekos\predict\キマイラベコ (8).JPGはユニベコーン! bekos\predict\キマイラベコ (9).JPGはキマイラベコ! bekos\predict\ケルベコス (1).JPGはケルベコス! bekos\predict\ケルベコス (2).JPGはユニベコーン! bekos\predict\ケルベコス (3).JPGはベコサス! bekos\predict\ケルベコス (4).JPGはベコサス! bekos\predict\ベコサス (1).JPGはベコサス! bekos\predict\ベコサス (2).JPGはベコサス! bekos\predict\ベコサス (3).JPGはベコサス! bekos\predict\ベコサス (4).JPGはベコサス! bekos\predict\ベコサス (5).JPGはベコサス! bekos\predict\ベコサス (6).JPGはミノタウベコ! bekos\predict\ミノタウベコ (1).JPGはミノタウベコ! bekos\predict\ミノタウベコ (10).JPGはミノタウベコ! bekos\predict\ミノタウベコ (11).JPGはミノタウベコ! bekos\predict\ミノタウベコ (12).JPGはミノタウベコ! bekos\predict\ミノタウベコ (13).JPGはミノタウベコ! bekos\predict\ミノタウベコ (14).JPGはミノタウベコ! bekos\predict\ミノタウベコ (15).JPGはミノタウベコ! bekos\predict\ミノタウベコ (16).JPGはミノタウベコ! bekos\predict\ミノタウベコ (17).JPGはミノタウベコ! bekos\predict\ミノタウベコ (2).JPGはミノタウベコ! bekos\predict\ミノタウベコ (3).JPGはミノタウベコ! bekos\predict\ミノタウベコ (4).JPGはミノタウベコ! bekos\predict\ミノタウベコ (5).JPGはミノタウベコ! bekos\predict\ミノタウベコ (6).JPGはミノタウベコ! bekos\predict\ミノタウベコ (7).JPGはミノタウベコ! bekos\predict\ミノタウベコ (8).JPGはミノタウベコ! bekos\predict\ミノタウベコ (9).JPGはミノタウベコ! bekos\predict\ユニベコーン (1).JPGはユニベコーン! bekos\predict\ユニベコーン (2).JPGはユニベコーン! bekos\predict\ユニベコーン (3).JPGはユニベコーン! bekos\predict\ユニベコーン (4).JPGはユニベコーン! bekos\predict\ユニベコーン (5).JPGはユニベコーン! bekos\predict\ユニベコーン (6).JPGはユニベコーン! bekos\predict\ユニベコーン (7).JPGはユニベコーン! bekos\predict\ユニベコーン (8).JPGはユニベコーン! bekos\predict\ユニベコーン (9).JPGはユニベコーン! 正解率:39/47(83%) |
正解率83%でした。
ミノタウベコは明らかに色が違うのでわかるとして、角しか特徴がないユニベコーンも全部合ってますね。
キマイラベコは特徴が多いのでいけそうな気がしてましたが、あまり良い結果になりませんでした。
画像が少なくても意外と当たる
今回、各50枚ずつという少ない画像で分類を行いました。
実は1つミスをしていたんですが、思っていたよりは精度が出たんじゃないかと思います。
(水増しした画像は、学習データの検証(x_test)に使ったらだめらしいです。。。)
あとは学習用の画像を増やしたり、できるだけベコだけ写っているようトリミングしたりすれば、精度90%越えもできるはず。
時間ができたらもう少しいじってみようと思います。
