いろいろあって、画像を収集するWEBスクレイピングツールを作りました。
目次
WEBスクレイピングツール
ソース
作成物はGitHubに。
機能概要
- Google or Bingから指定クエリで指定枚数の画像をダウンロードする
- すでに保存済みの画像と同じものがあれば保存しない
開発環境
Windwos10 + Anaconda Python3.7 + VSCode
環境準備
Anacondaを使った場合で説明。
Anacondaはインストールして使える状態にしておいてください。
仮想環境作成
ターミナルやAnaconda Promptで以下のコマンドを実行。
仮想環境名をscrapingとした場合は以下。
|
1 |
conda create -n scraping python=3.7 |
色々出てきたら、yを押して作成完了。
必要なパッケージをインストール
ターミナルやAnaconda Promptで以下のコマンドを実行。
|
1 |
conda activate scraping |
仮想環境に入れたら、以下をインストール。
|
1 2 3 |
conda install requests conda install beautifulsoup4 conda install lxml |
ソースを配置
仮想環境を作成したら、/Anaconda3/envs/の中にディレクトリができているので、そこにファイルを追加。
|
1 2 3 4 5 |
scraping ├src //srcをそのまま置く └Lib └site-packages └importpath.pth // site-packagesの中にimportpath.pthを追加 |
ファイルの修正
import用パス
importpath.pthのパスを自分の環境に合わせて書き換え。
|
1 2 |
C:/Anaconda3/envs/scraping/src C:/Anaconda3/envs/scraping/src/common |
プロキシの設定
プロキシを使っている場合はCommonConst.pyの【PROXIES】を設定。
画像の保存ディレクトリ
変更する場合はCommonConst.pyの【DATA_DIR】を変更。
デフォルトは以下。
|
1 2 3 4 5 6 |
scraping └download // ここのパスは変更できる ├tmp // 作業用 └猫 // 検索キーワードごとにディレクトリができる ├00001.jpg └00002.png |
使い方
ターミナルやAnaconda Promptで以下のコマンドを実行。
パラメータは4つ。
- 実行ファイル名:SearchEngineClass.pyを指定
- 検索サイト:google or bingを指定
- 検索キーワード:画像検索で使用するキーワードを指定
- 取得枚数:ダウンロードする枚数を指定
|
1 2 3 4 5 |
// Google画像検索で猫を検索し、画像を10枚ダウンロードする python SearchEngineClass.py google 猫 10 // 2つのキーワードを使用し、bingから画像を100枚ダウンロードする python SearchEngineClass.py bing "猫 黒い" 100 |
検索キーワードに含まれるスペースはアンダーバーに変換されます。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
(scraping) C:\Anaconda3\envs\scraping>python src/SearchEngineClass.py google "猫 黒" 10 画像URLの収集を開始します 画像URLの収集が完了しました ダウンロードを開始します 同じ画像が既に存在します 同じ画像が既に存在します 同じ画像が既に存在します 同じ画像が既に存在します 画像以外のファイルです 同じ画像が既に存在します 画像以外のファイルです ダウンロードが完了しました {'download': ['C:/Anaconda3/envs/scraping/download/image/猫_黒/00006.jpg', 'C:/Anaconda3/envs/scraping/download/image/猫_黒/00007.jpg', 'C:/Anaconda3/envs/scraping/download/image/猫_黒/00008.jpg'], 'download_error': ['https://images.pexels.com/photos/566872/pexels-photo-566872.jpeg?cs=srgb&dl=-566872.jpg&fm=jpg', 'https://images.pexels.com/photos/1182924/pexels-photo-1182924.jpeg?cs=srgb&dl=-1182924.jpg&fm=jpg'], 'download_skip': ['C:/Anaconda3/envs/scraping/download/image/猫_黒/00001.jpg', 'C:/Anaconda3/envs/scraping/download/image/猫_黒/00002.jpg', 'C:/Anaconda3/envs/scraping/download/image/猫_黒/00003.jpg', 'C:/Anaconda3/envs/scraping/download/image/猫_黒/00004.jpg', 'C:/Anaconda3/envs/scraping/download/image/猫_黒/00005.jpg']} |
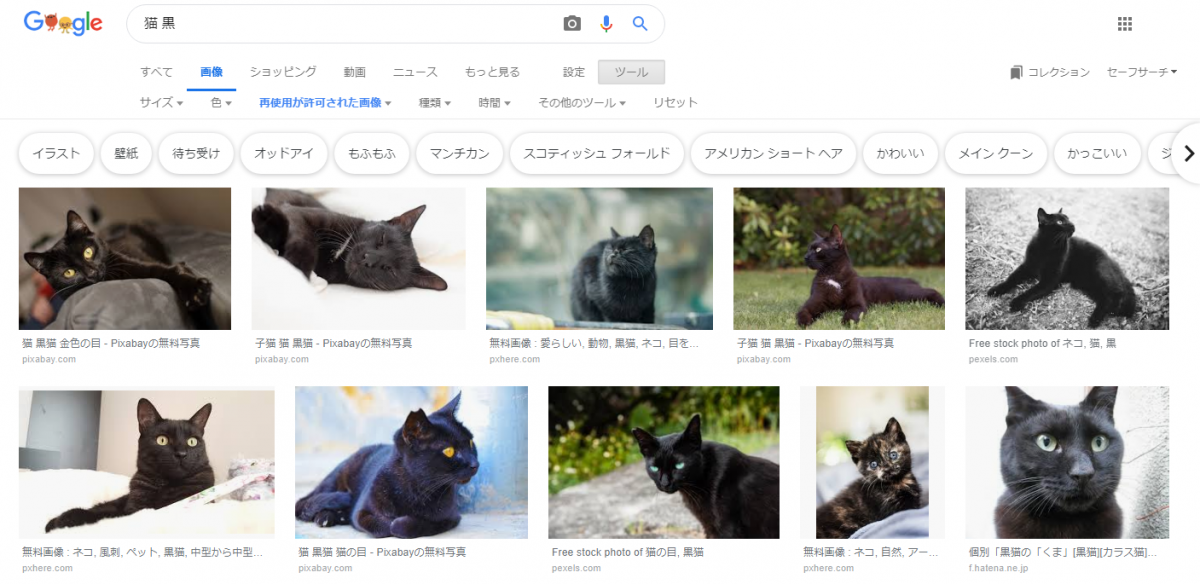
実際にダウンロードした画像

戻り値
download
ダウンロードに成功した場合、保存した画像のパスを返します。
download_error
何らかの理由でdownloadに失敗した場合、対象の画像URLを返します。
現状、画像URLの末尾が画像の拡張子じゃない場合はエラーになります。
download_skip
ダウンロードした画像がすでに保存している画像と同じものだった場合、保存済みの重複画像のパスを返します。
注意
WEBスクレイピングツールはやろうと思えば何でも取得できます。
でも法律に抵触するようなことはやっちゃダメ。
ということで、ライセンスフリーの画像のみ集めるようにしてみました。
これだと版権系の画像はほとんどヒットしないはずです。
いや、俺は嫁の画像をたくさん集めたいんだ!!
という場合は、以下をコメントアウトすればフィルターが解除されます。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
# Googleの場合 while True: params = urllib.parse.urlencode({ 'q':keyword, 'tbm':'isch', # 'tbs':'sur:fc', 'ijn':str(page)}) yield SEARCH_URL[site] + '?' + params page += 1 # Bingの場合 while True: params = urllib.parse.urlencode({ 'q':keyword, # 'qft':'+filterui:license-L1', 'first':str(item)}) yield SEARCH_URL[site] + '?' + params time.sleep(1) item += self.item_count |
もしバグってたら
コメントかTwitterで教えてください。
(直すかどうかは不明)
ソースの説明は…次回?
